键空间
Redis是一个key-value数据库,RedisServer中有多个数据库,每个数据库都由一个redisDb结构表示,其中的dict字典保存了数据库中所有的键值对,dict称之为键空间:
- key就是数据库的键;
- value就是数据库的值,具体为字符串、列表、哈希、集合、有序集合中的一种;
假设这是一个现有的键空间:
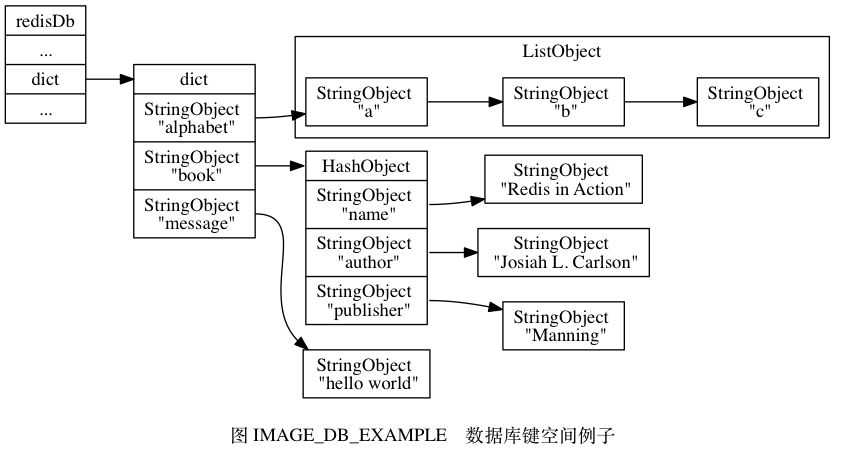
添加键:

Redis是一个key-value数据库,RedisServer中有多个数据库,每个数据库都由一个redisDb结构表示,其中的dict字典保存了数据库中所有的键值对,dict称之为键空间:
假设这是一个现有的键空间:
添加键:
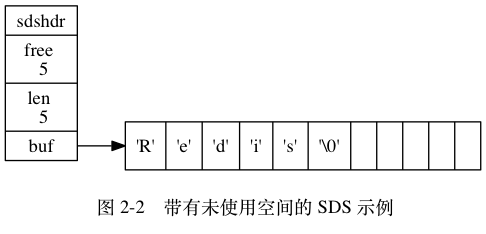
Redis只使用C字符串作为字面量,其他地方都使用SDS来表示字符串,定义如下:
1 | // 简单动态字符串 |
| C字符串 | SDS |
|---|---|
| 获取strlen为O(N) | 获取strlen为O(1) |
| API不安全,缓冲区可能溢出 | API安全,缓冲区不会溢出 |
| 修改字符串N次必然需要N次内存重分配 | 修改字符串N次最多需要N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或二进制数据 |
| 可以使用所有\<string.h>函数 | 可以使用部分\<string.h>函数 |
先放上我个人认为很帅的图标:![]()
谈到Haskell,当时我只是在网上偶然看到函数式编程,便起了兴趣,想去了解一下,毕竟大学时间比较多,多了解一些东西也是好的。经过知乎上一番搜索,最后是选择了Haskell来了解函数式语言,因为它比较纯(然而我现在也没接触过其他函数式语言,Lisp,Scala等,也不太懂到底怎么纯的……)。
既然想学,就要去搜一些Haskell的学习资料啦,现在让我来推荐的话,《Learn You a Haskell for Great Good!》、《Haskell WikiBook》、《Real World Haskell》大概是这三本,然后做做H-99: Ninety-Nine Haskell Problems就差不多入门了吧,然而我只看了第一本,初步领略了一下函数式编程的乐趣(?)就没再看了。
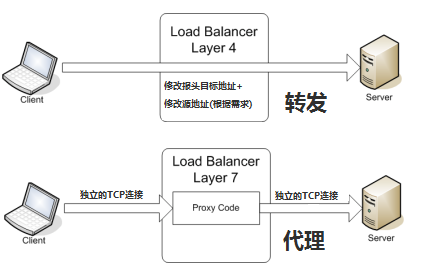
我们都知道,当我们上网时,服务器无时无刻工作着,为我们提供服务。随着互联网的发展,业务流量越来越大且业务逻辑越来越复杂,单机服务器的性能已无法满足业务要求,为此,我们需要多台服务器进行性能的水平拓展,但如何平均地将流量分发到多台服务器上呢?这就是负载均衡。
负载均衡整体上分为两大类:
C++作为一门极其复杂的语言,使用好它是十分困难的,C++的灵活语法和复杂特性使得C++变得无比强大,但这也导致它变得十分复杂,曾经我觉得使用越多高级特性的代码就越厉害,而现在我无法赞同,绝大多数情况下,代码的可读性和可维护性是第一位的,而C++正是因此而变成了“最难”的语言,不同人、团队的C++代码风格相差甚远,各种技巧用得飞起,在这种情况下,如果能有一个规范,使得代码尽量统一,就能在一定程度上解决C++代码难以维护的问题。
尽管Google C++代码风格是针对Google自身情况制定的,限制和禁止了很多特性(由于历史原因等),但对于我这种新手,仍十分有帮助。
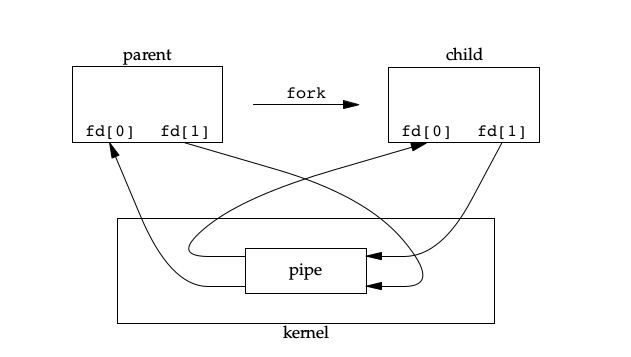
1 | int pipe(int fd[2]); |
通常用法是先pipe,然后fork,这样父子进程就可以通信:
读一个写端已关闭的管道,在所有数据都读取后,read返回0,表示文件结束;
对于可能使进程永远阻塞的系统调用,如果不想进程一直阻塞,可以将系统调用设为非阻塞:
这样,如果系统调用无法满足要求,会立刻返回并设定相应错误标志。
记录锁保证不会有多个进程同时修改一个文件的同一区域,设置记录锁的POSIX方法是通过fcntl:
1 | int pthread_equal(pthread_t tid1, pthread_t tid2); |